
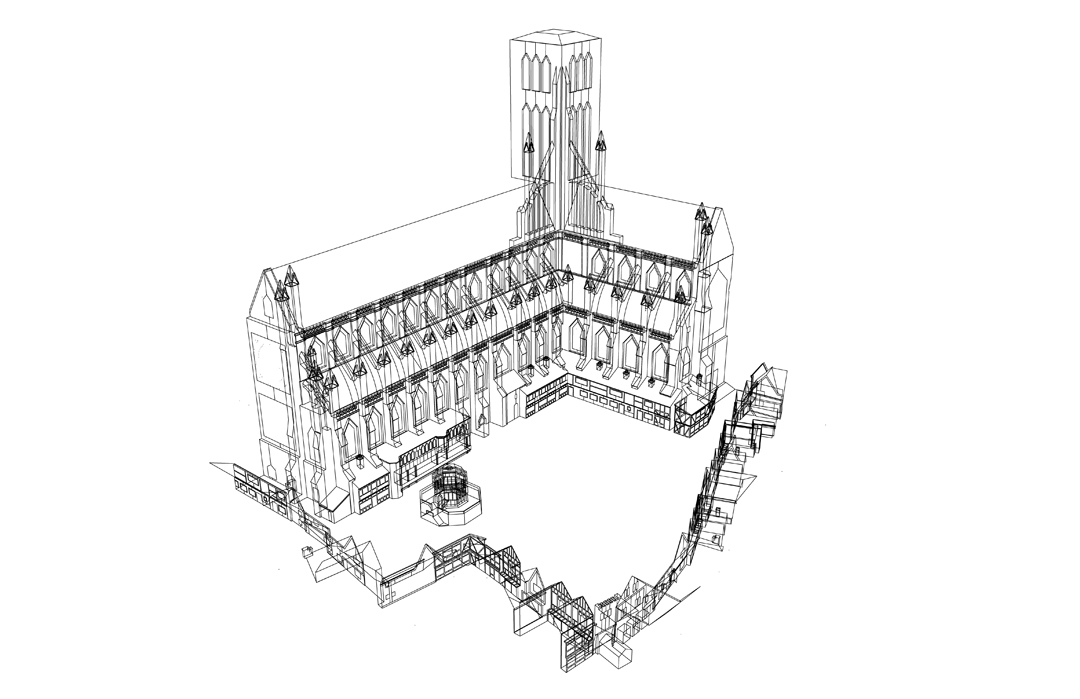
 Figure 1: Wireframe Image of the Acoustic Model, Paul’s Churchyard, the Cross Yard. Wireframe from the Visual Model, constructed by Joshua Stephens.
Figure 1: Wireframe Image of the Acoustic Model, Paul’s Churchyard, the Cross Yard. Wireframe from the Visual Model, constructed by Joshua Stephens.
THE ACOUSTIC MODEL
The sound of the Virtual Paul’s Cross Project has been the work of Ben Markham and Matt Azevedo, acoustic engineers with Acentech Incorporated, acoustic consultants, at 33 Moulton Street, in Cambridge, MA.
The acoustic model of Paul’s Churchyard was constructed by Ben and Matt, working from a simplified version of the visual model that was constructed by Josh Stephens and adapted by him to fit the requirements of the CATT acoustic modeling program.
The acoustic model of St Paul’s Cathedral and Paul’s Churchyard simulates the experience of early modern preaching in London by enabling us to hear a Paul’s Cross sermon as an event that unfolds in real time in the specific space of the northeast corner of Paul’s Churchyard.
The behavior of sound in space is well-understood today. We know that sound, once made, travels at a certain speed until it bumps into something, at which point it is either absorbed, reflected, or dispersed, depending on the shape of the object it hits and the materials out of which the object is made.
Paul’s Churchyard was a large open space some 235 feet by 185 feet wide in the center of a large and rapidly growing city. The activities of the approximately 200,000 people living in and around London in the early 1600’s generated much of the background noise. The rest came from physical aspects of the place, from the sounds of water, wind, and animals. This meant that the preacher’s words were only part of what people gathered for these sermons could hear during the course of the sermon.
The acoustic model was then constructed by Ben Markham and Matt Azevedo of Acentech Incorporated, in Cambridge, Massachusetts, using the CATT acoustic modeling program, based on a Josh’s simplified version of the visual model.
Joshua Stephens, who built the visual model, revised his model for acoustic modeling purposes and supplied Ben and Matt with an account of the materials used in the construction of the original buildings.
Ben and Matt have created the acoustic model of St. Paul’s and Paul’s Churchyard, guided the recordings of Donne’s Gunpowder Day sermon, the crowd noises, and other ambient sounds, and created the program that blends all these together into the recordings available on this website.
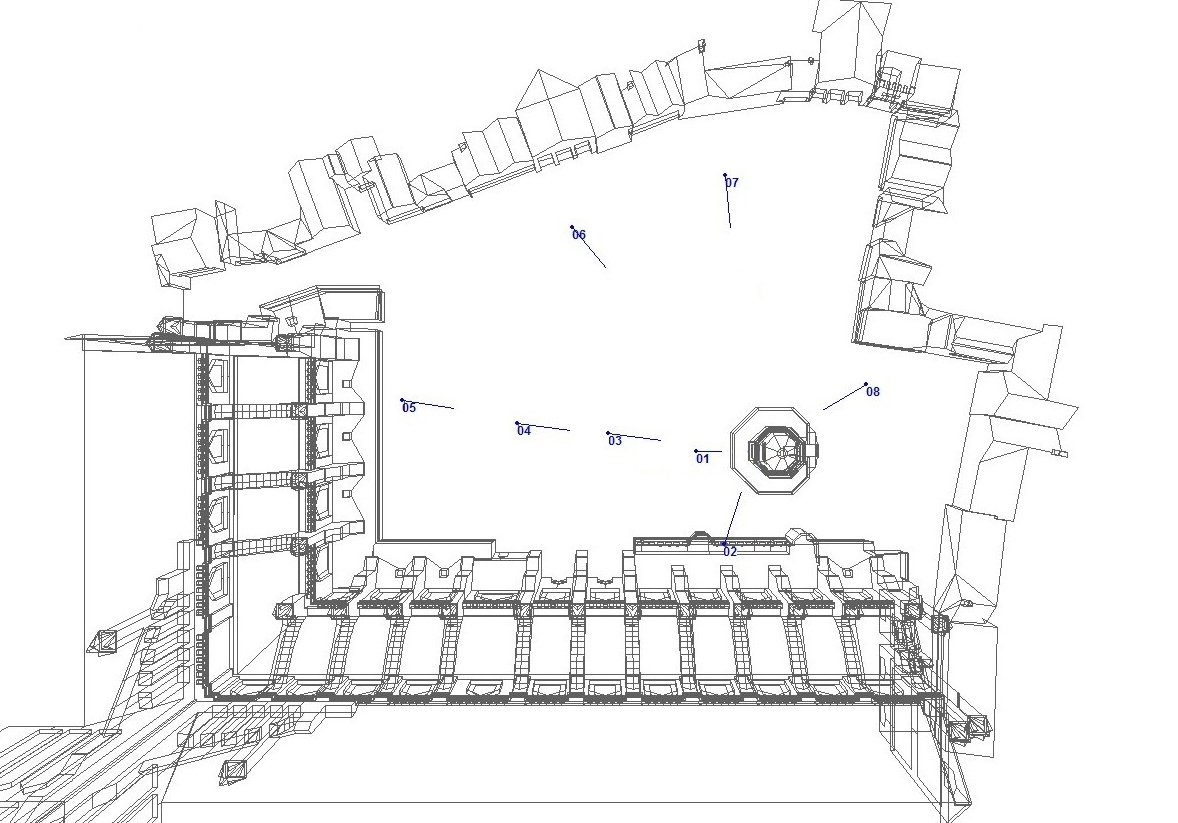 Figure 2: Wire frame View of the Acoustic Model, Paul’s Churchyard, the Cross Yard. Wire frame from the Visual Model, constructed by Joshua Stephens.
Figure 2: Wire frame View of the Acoustic Model, Paul’s Churchyard, the Cross Yard. Wire frame from the Visual Model, constructed by Joshua Stephens.
Ben Markham supplies us with a more detailed account of the acoustic properties of this space in his Acoustic Engineer’s Report, below.
Acoustics at Paul’s Cross
Ben Markham
Director, Architectural Acoustics
Acentech Incorporated
Accounts of the events at Paul’s Cross vary regarding the size of the crowd that might have gathered there in the 1620s to hear John Donne and others speak. Among the goals of the Virtual Paul’s Cross Project is to not only simulate the aural and visual experience of such an event, but to learn just how many people might reasonably have been able to hear a speech there intelligibly. Paul’s Cross was a large enough space that listeners might conceivably have been well over 100 feet from the speaker – how well could they have heard? The answer depends on the ratio of (a) how loud the speech is at a given listening position – the “signal” – to (b) the loudness of ambient noise in the area – the “noise.” To understand what the signal-to-noise ratio might have been in Paul’s Cross at various locations, we look at those two components separately.
What kind of speaker was John Donne?
We have no way of knowing exactly how loud John Donne spoke, or precisely what his cadence was. The anechoic recording used to simulate the Gunpowder Sermon features an actor who delivers a speech consistent with a practiced orator delivering a speech to a great outdoor crowd: the voice is strong, the cadence measured. Speech varies in loudness continuously, but we have modeled a typical sustained sound pressure level of approximately 75 dB at a distance of 3 feet from the speaker, which is consistent with standards for loudness of raised vocal effort. As discussed below, the slow cadence and emphasis of certain phrases helps to improve intelligibility by overcoming the effects of reverberation, ambient noise, and listeners’ imperfect attention.
Paul’s Cross is not an Open Field
To understand how loud speech was in Paul’s Cross, it is useful to compare our model of the loudness of speech there to what one would perceive of a speech given in an open field.
In a perfectly open field, with no nearby buildings around to bounce sound back to the listener, sound decays by 6 decibels per doubling of distance from the source. In other words, if John Donne’s speech was 75 dB at the ears of a listener a mere 3 feet away, that same speech – if given in an open field – would be only 69 dB at 6 feet, 63 dB at 12 feet, and 57 dB at 24 feet. A listener 96 feet from the speaker would receive only 45 dB of sound from speech in an open field, and would have struggled to hear (for reasons we discuss later). Paul’s Cross, however, was no open field – the courtyard was surrounded with buildings: the Cathedral most prominently, but also an assortment of merchant buildings that surround the courtyard almost completely.
The graph below charts the sound pressure level (on the vertical axis) versus the distance from the speaker (the horizontal axis), comparing our model of Paul’s Cross to a perfectly open field. At distances as great as 140 feet or more from the speaker, our model predicts that sound levels from speech were around 55 dB, thanks to sound reflections from the nearby buildings. In an open field, sounds at those distances would be less than 45 dB – a 10 decibel difference. A 10 decibel drop in sound level is perceived as about a halving of loudness. In other words, at a significant remove from the speaker, listeners in Paul’s Cross likely perceived speech at a level as much as twice as loud as they would have were the speeches presented in an open field.

Figure 3: Graph showing sound level versus distance modeled in Paul’s Cross (blue) as compared to a perfectly free field (red).
Ambient noise
The loudness of speech is not the only factor that affects intelligibility – so too does the loudness of ambient noise. In an outdoor setting, speech must compete with all the rest of the noises of city life to be heard clearly. However, in the pre-industrial London of 1622, ambient noise was not what it is today.
Modern cities produce background noise levels that vary between 45 and 65 decibels depending on the time of day and the level of activity nearby. Most of that noise is generated by the products of advancements since the Industrial Revolution: mechanical heating and cooling systems, for example, and most especially, vehicular traffic.
That said, the pre-industrial urban soundscape was by no means silent. A casual listener to our auralization of Paul’s Cross will hear the flutter of pigeons, a horse walking near the perimeter of the courtyard, and a host of other “natural” sounds. Importantly, people make noise too – the sounds of listeners shuffling their feet or mumbling to their neighbor are as distracting to a speech as they are today. But instead of a steady mid-day background noise level of perhaps 45 to 50 decibels or more, the steady-state ambient noise of the day was perhaps closer to 35 decibels at the critical frequencies when people were quiet and listening. In other words, background sound in Paul’s Cross in 1622 might have been more than 10 decibels quieter than it is now – less than half as loud.
Signal to noise ratio
The intelligibility of speech, or other sounds for that matter, is related to both of these factors: not just to the loudness of speech, and not just to the loudness of competing noise, but to the ratio of these factors. To promote good speech intelligibility, the difference in decibels between the speech signal and the steady-state background sound should be at least 15 decibels. In an open field with a 1622 background noise of 35 dB, the difference between speech and background noise would be only about 7 decibels at a distance of 140 feet from the source (42 dB of speech minus 35 dB of noise). In a speech at Paul’s Cross with a modern-day background noise level of 50 dB, the difference between signal and noise would be only 5 decibels at a distance of 140 feet (55 dB of speech minus 50 dB noise). However, in Paul’s Cross in 1622, the signal to noise ratio was more favorable than either of these hypotheticals: the difference between speech at 140 feet (55 dB) and 1620s background sound (roughly 35 dB) is as much as 20 dB – sufficient for a high degree of speech intelligibility. Of course, this would have been interrupted at times by the sounds of people talking or other activity sounds, much as at any modern open-air speech event.

Figure 4: Speech signals relative to background noise under three scenarios. Note that in Paul’s Cross, relative to the noise levels of 1622, the signal-to-noise ratio (in red) is greater than either of the other two hypothetical scenarios.
Reverberation
Because of the reflections from buildings around Paul’s Cross, not only is speech louder, it is also somewhat more reverberant. In an open-air environment, much of the sound escapes to the sky, preventing excessive reverberation. However, late arriving sound reflections from buildings can create some reverberation that will muddy speech. In Paul’s Cross, as in most open-air spaces, the effect on intelligibility is perceivable, particularly in locations that are near the center of the courtyard (farthest from reflective building surfaces), but marginal. Further, a measured cadence of speech helps to avoid the deleterious effects of reverberation.
Non-Acoustic factors
Although acoustics plays a prominent role, other factors affect speech intelligibility as well. Listeners who can see the speaker, for instance, take in visual cues (facial expressions, lip reading, etc.) which aid intelligibility. Native familiarity with the language – and dialect – is also an important factor; most modern ears are not accustomed to the word choice or the accent of 17th century Britons. Speaking style, annunciation, and cadence all contribute significantly to intelligibility as well.
Of course, the proof is in the hearing: we encourage anyone interested in the Virtual Paul’s Cross project to hear the simulation and form their own judgments about the audibility, clarity, and intelligibility of speech there.